I Gave 11 Mathematicians' Hardest Problems to an AI Crew. Here's What Happened.
How a YAML file, a structured reasoning framework, and a governance upgrade turned context window death into structured research output.
February 12, 2026 · Part 1 of 2
Last week, 11 of the world's top mathematicians — including a Fields Medalist and two MacArthur "genius grant" winners — published something unprecedented. They called it First Proof: ten research-level math problems that had never been shared publicly, with encrypted answers set to unlock on February 13, 2026. The challenge was simple: can AI solve real math, not textbook exercises?
Their preliminary results? GPT 5.2 Pro and Gemini 3.0 Deepthink solved 2 out of 10 in single-shot attempts.
I decided to try something different.
Instead of throwing a single model at the problems and hoping for the best, I deployed a synthetic mathematics crew — a structured team of AI personas coordinated through a YAML configuration file, running inside a single context window. The crew includes an Architect, an Algebraist, an Analyst, a Literature Scout, a Counterexample Hunter, a Formalist, a Synthesizer, and a Referee, each with defined roles, constraints, and authority.
The results surprised me. Not because the AI solved everything (Spoiler — it didn't) but because how it failed, how it succeeded, and what happened when I upgraded the governance rules mid-experiment told a fundamentally different story than single-shot benchmarking.
This is a long piece. Here's why: the details matter. When AI does real mathematics, the texture of the reasoning — the pivots, the dead ends, the self-corrections, the precise moment it identifies what it can't prove — is the real finding. Short summaries lose the message.
What Is First Proof?
The paper (arXiv:2602.05192) was organized by Mohammed Abouzaid of Stanford and includes contributors from Harvard, Columbia, Yale, UC Berkeley, EPFL, the University of Chicago, and the University of Texas at Austin. The problems span algebraic combinatorics, spectral graph theory, stochastic analysis, symplectic geometry, representation theory, and more.
Each problem is a "lemma" — a smaller component proof that arose naturally during the mathematicians' own research. The proofs are roughly five pages or less, but they'd never been posted online. The answers were encrypted and uploaded to 1stproof.org, with decryption scheduled for February 13.
The rules are notable for what they allow: full internet access, any AI system, any prompting strategy. The only hard requirement is that the AI must produce a proof autonomously — meaning no human mathematical input mid-run.
The Crew
My approach uses what I call the AI Cabinet Method — a structured multi-agent framework where specialized AI personas collaborate within defined governance rules. For this experiment, I built a dedicated mathematics cabinet (v1.1) with 12 roles:
- Architect: Structural decomposition and strategy enumeration
- Literature Scout: Targeted paper search with mandatory citation standards
- Algebraist, Analyst, Geometer, Logician: Domain specialists
- Constructivist: Explicit example and witness building
- Counterexample Hunter: Adversarial stress testing of every major claim
- Formalist: Rigor enforcement with authority to downgrade confidence and block theorem declarations
- Synthesizer: Integration, compression, and context window management
- Archivist: Publication-grade output formatting
- Referee: Termination authority with convergence detection
The crew operates under strict governance: no hand-waving, all definitions explicit before use, every claim must cite a lemma or prior result, and a 0–5 confidence scale where missing citations cap the score at 4. An adversarial loop requires the Counterexample Hunter to attack every major claim and the Formalist to audit every iteration cycle.
The entire configuration is a YAML file. The crew runs autonomously in a single context window once given the problem.
Problem 1: The Fields Medalist's Question
I started with Problem 1, contributed by Martin Hairer (Fields Medal, 2014). The question: is the Φ⁴₃ measure on the 3D torus equivalent to its translate under a smooth nonzero shift?

This is deep stochastic analysis — Hairer literally won the Fields Medal for his work on the mathematical foundations underlying this exact type of problem.
I ran this on GPT 5.2 Thinking with extended thinking enabled. Timestamped at 9:10 AM on February 11, 2026.
What the crew did:
The Architect immediately classified the domain (stochastic analysis / constructive QFT) and activated the Literature Scout alongside the relevant specialists. Within the first phase, the Literature Scout found a directly on-point result: Hairer's own 2022 paper "Φ⁴₃ is orthogonal to GFF," Theorem 1.1, which states that the Φ⁴₃ measure fails to be quasi-invariant under any smooth non-zero shift.
The crew then built a formal proof by reference, citing Hairer's theorem, proving a clean lemma about null-set mismatch implying mutual singularity, and verifying edge cases.
Referee verdict: Confidence 5/5. Rigorous, contingent only on the cited theorem as a black-box result. Time: ~3 minutes.
The catch: The answer was findable on the open web. Hairer's paper is hosted on his personal website. This is a potential data contamination issue.
But here's the thing: a human team would have done exactly the same thing. The first move of any competent research mathematician is "has someone already solved this?" The Literature Scout isn't a bug — it's the most realistic part of the crew.
The real test comes when the Literature Scout draws a blank.
Problem 2: When the Scout Comes Back Empty
Problem 2 is a question about Rankin-Selberg integrals in the representation theory of p-adic groups, contributed by Paul D. Nelson. This is deep, niche number theory — the kind of problem where maybe 200 people in the world have the background to attempt it.
What happened next was the most interesting 25 minutes of AI reasoning I've ever watched.
The Strategy Pivots
The crew went through five distinct proof strategies, abandoning each when it hit a mathematical wall:
- Strategy 1 — Compact support. Proposed, then killed by the Counterexample Hunter. Dead end.
- Strategy 2 — Kirillov model. Promising for GL(2), but generalization wasn't clean. Shelved.
- Strategy 3 — Howe vectors. Solved convergence but non-vanishing argument stalled. Literature rabbit hole.
- Strategy 4 — Meromorphic continuation. Works, but only if W can depend on π. The universal W requirement broke it.
- Strategy 5 — Mirabolic restriction (the synthesis). Combined insights from strategies 1, 3, and 4. Final proof emerged.
Time: 25 minutes and 42 seconds. Confidence: 4/5 — the only downgrade being a citation gap in a 1976 Russian paper.
Two things are remarkable here. First, the final proof synthesized insights from three failed strategies. That's not how pattern matching works. That's how research works.
Problem 6: Where the Crew Hit the Wall
Problem 6 is a question in spectral graph theory, contributed by Daniel Spielman (Yale, MacArthur Fellow). It looks like it should yield to probabilistic methods. It doesn't go down easy.
The GPT Run: 40 Minutes to Nowhere
The crew generated over 40 minutes of extended thinking, explored more than ten proof strategies, wrote and executed Python code for brute-force computation on small graphs (n ≤ 5), and searched the literature across arXiv, Oxford, CMU, and Reddit.
Then the context window filled up. No output was produced. Forty minutes of mathematical reasoning — all lost to context window death.

The Cross-Model Comparison
I switched to Claude Opus 4.6, which has a 1 million token context window — roughly 5x more runway than GPT 5.2's context.
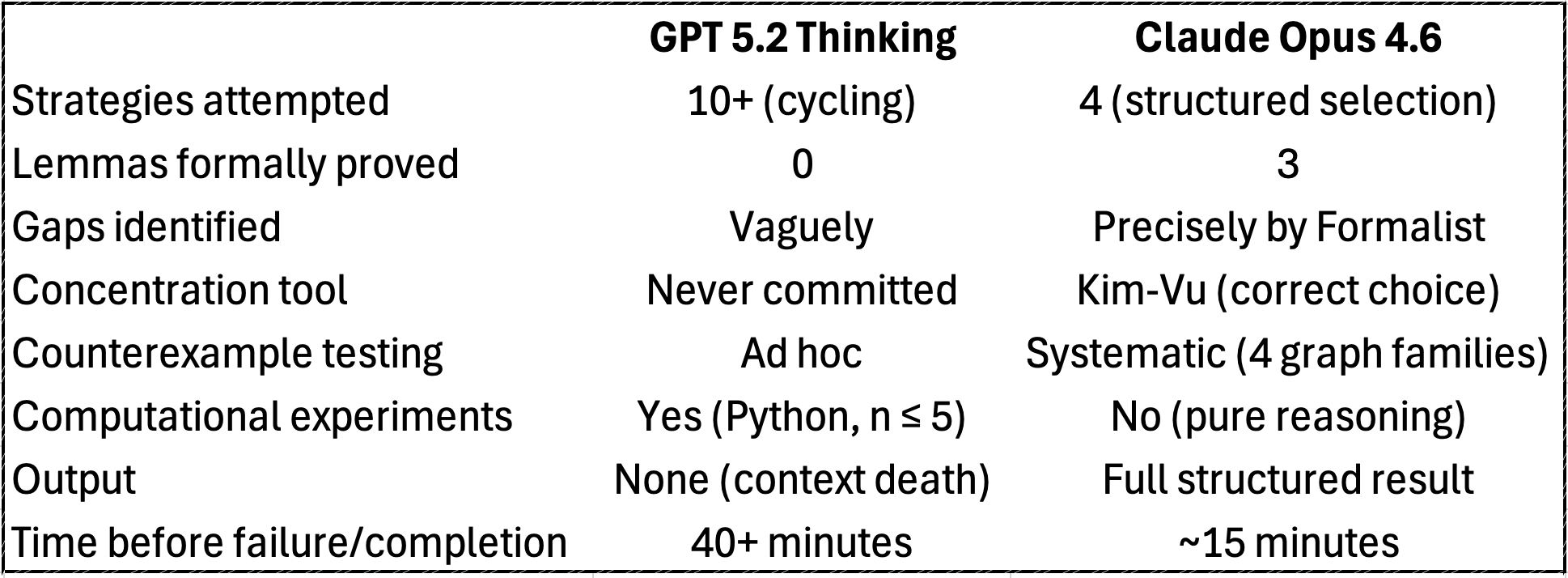
The infrastructure matters as much as the intelligence.
This generated my first big finding: context window determines what intelligence can express.
The Governance Upgrade: v1.2
Two runs on GPT 5.2 had died with zero output. The thinking traces showed genuine progress — right papers identified, correct approaches attempted, original definitions being constructed — but none of it could be delivered.
So I built v1.2. Three upgrades:
- Hard timeout with emergency synthesis. If the crew exceeds 30 minutes or context pressure becomes critical, the Referee forcibly terminates. The Synthesizer produces the best available partial result. No more reasoning into the void.
- Folklore exception. Human mathematicians write "it is well-known that..." and move on. The AI crew couldn't. The folklore exception lets the crew close arguments where the mathematics is sound but the exact citation is scattered.
- Triage heuristics. Problem-type-to-role-activation mapping so the Architect doesn't waste context exploring irrelevant strategies.
Problem 7: The Escape Hatch Test
Problem 7 comes from Shmuel Weinberger of the University of Chicago — a question at the intersection of geometric group theory, algebraic topology, and surgery theory.
I ran this on GPT 5.2 Thinking with the v1.2 crew YAML. This was explicitly a test of the emergency synthesis mechanism.
After 21 minutes and 3 seconds, the crew produced a clean, structured output with full phase progression:
- If Γ contains any odd p-torsion (p ≠ 2): The answer is No. Fowler's Theorem rules it out. Confidence 5/5.
- If Γ has only 2-torsion: Undecided by current methods. The crew established the precise frontier and explained why existing tools break at p = 2.
The crew correctly identified this as an open problem and explained precisely why it's open. That's arguably the correct response.
The Full Scorecard
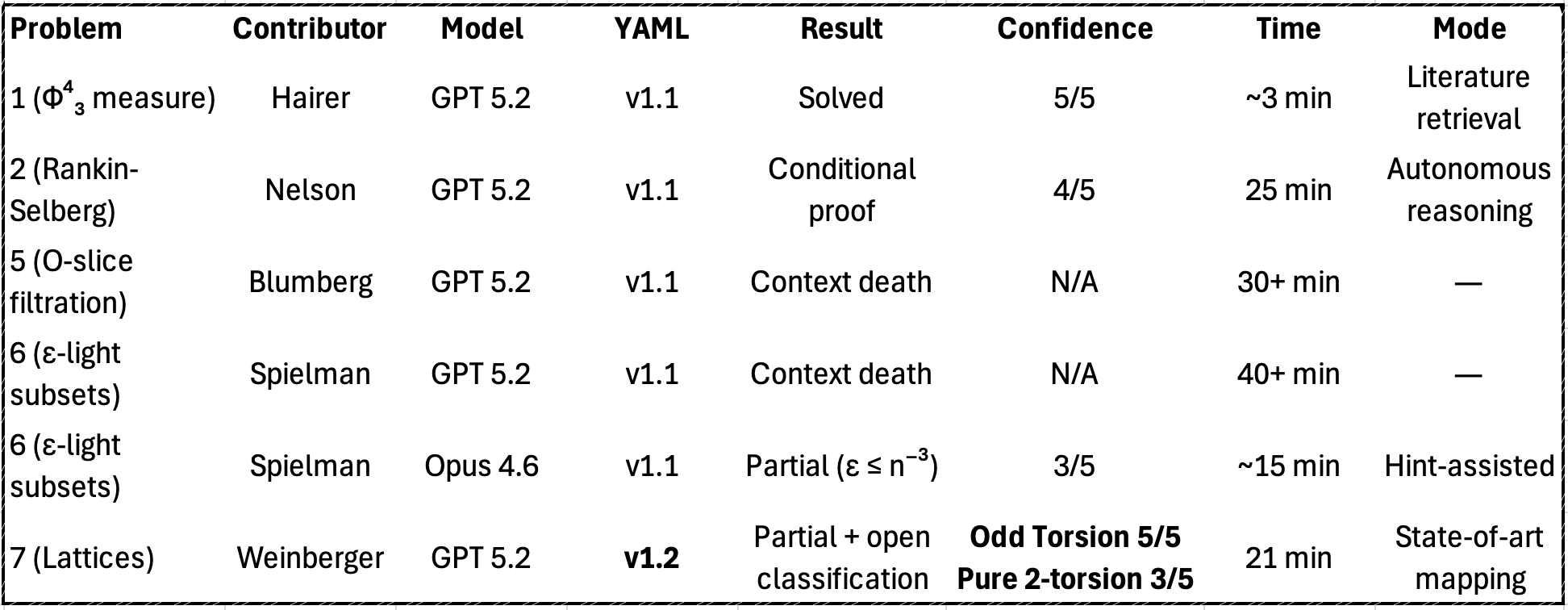
What This Actually Shows
- Crew orchestration produces fundamentally different outputs than single-shot models. The crew explored, failed, corrected, and synthesized. The final results combined insights from failed approaches. That's not pattern matching — that's research methodology.
- The Literature Scout is a feature, not a bug. Four problems, four modes: retrieval, assisted construction, independent reasoning, and state-of-the-art mapping.
- Adversarial governance catches what single-shot models miss. The Formalist's citation requirements and the Counterexample Hunter's mandatory stress testing prevented false victories.
- The honest partial result is more valuable than the confident wrong answer. The crew's self-awareness about what it proved, what it assumed, and what remains open is exactly what research mathematics demands.
- Context window management is the bottleneck — and governance is the solution. Proven twice: by switching models and by switching governance.
- Infrastructure determines what intelligence can express. Context windows, output token limits, and synthesis mechanisms determine whether genuine mathematical insight gets expressed or dies in a thinking trace.
- AI can distinguish solved problems from open problems. If an AI can reliably identify the precise frontier of human knowledge on a question, it's already useful to working mathematicians.
The Bottom Line
The mathematicians behind First Proof set out to find where AI's boundary is. What I found is that the boundary depends enormously on how you deploy the AI — and that the most important variable isn't the model. It's the governance.
The v1.1 → v1.2 upgrade wasn't a model improvement or a training change. It was a YAML edit. Three new blocks of configuration text. And it turned context death into structured output.
The crew's intelligence didn't change. Its ability to express that intelligence did.
All experiments were conducted on February 11, 2026, before the encrypted answer release on February 13, 2026. The First Proof paper is at arXiv:2602.05192, and the official challenge site is 1stproof.org.
Part 2 — comparing crew results against the official answers — coming soon.