From LinkedIn Scroll to Working Prototype in Two Hours
A Build-in-Public Story About AI-Augmented Product Development
January 31, 2026
Two perspectives on the same Saturday morning. Part 1 is the human side — opportunity recognition, product strategy, and spec development. Part 2 is the crew side — how AI agents turned that spec into tested, shippable code. Together, they document a complete product development cycle: idea → research → spec → implementation → QA → bug fix → re-validation → approved.
Part 1: Opportunity → Strategy → Spec
Mike + Claude
7:03 AM — A Screenshot and a Gut Feeling
It started with a LinkedIn post.
I was scrolling my feed on a Saturday morning and spotted a post from Evan Glaser (Founder & CEO, Alongside AI) breaking down a new Anthropic research paper. The study — "How AI Impacts Skill Formation" by Judy Hanwen Shen and Alex Tamkin, published January 29, 2026 — had tracked 52 junior developers learning Python's Trio library. The ones using AI assistance scored 17% lower on comprehension tests than those coding by hand. Debugging skills took the biggest hit. The comments were blowing up.
I screenshotted the post and an embedded Reddit thread from r/ClaudeAI, opened a conversation with Claude, and started talking.
The instinct was immediate: this isn't just a concerning study. It's a product opportunity.
7:05–7:20 AM — Divergent Thinking, Then Convergence
The initial conversation wasn't about building anything. It was about understanding the space. We discussed three angles: a LinkedIn thought leadership play leveraging my delivery org experience, positioning for Crewly Codes V2, and an academic research response building on my published work.
Then I pivoted. Instead of responding to the study, I wanted to solve the problem it identified.
"I was thinking about pretraining on known programming patterns and building a super-linter that doesn't just catch errors, but explains why they're errors and what the fix should be."
That reframed everything. The study said developers are losing debugging skills. The industry response would be "use less AI." My response: build AI that catches what developers can't — and teaches them in the process.
Don't fight the trend. Instrument it.
7:20–7:45 AM — Rapid Spec Development
What followed was a fast-moving product design conversation. Not a formal requirements session — a collaborative back-and-forth where ideas got pressure-tested against data in real time.
Key decisions made in this window:
- Standalone tool, not a feature. My first instinct was to embed this in Crewly Codes. Wrong. A standalone tool that works on any code — human or AI-generated — addresses every developer shipping AI-assisted code. That's the whole market.
- Fine-tuned model, not a wrapper. This was the critical insight. If frontier models like GPT-4 and Claude were already good at catching their own mistakes, developers would just ask their AI assistant "what's wrong with this code?" and the gap wouldn't exist. A general-purpose model with a clever prompt isn't a product — it's a weekend hack. A purpose-built model trained specifically on pattern detection and explanation is defensible IP.
- Local-first, no cloud dependency. No data leaving the machine, no SOC 2 conversations, no storage infrastructure to manage. "Your code never leaves your machine" becomes a headline feature, not a limitation.
- CLI + VS Code, privacy by architecture. The interfaces developers already live in. No new workflow. No accounts.
Research that informed the spec:
During the conversation, we pulled and synthesized data from multiple sources as decisions needed validation:
- The original Anthropic paper (arXiv:2601.20245) — study design, the six interaction patterns, specific metrics including that the "Generation-Then-Comprehension" pattern scored 86% on comprehension while pure "AI Delegation" scored 39%
- BugWhisperer (IEEE VTS 2025) — showed fine-tuned Mistral-7B jumped from 42.5% to 84.8% accuracy on vulnerability detection, a 42-point improvement validating the fine-tuning thesis
- Competitive landscape of AI linting tools (CodeRabbit, SonarQube, Cursor BugBot, DeepCode/Snyk) — confirming the teaching layer is unoccupied
This wasn't sequential research. It was pulled as decisions needed data, woven into a spec taking shape in parallel.
7:45–8:15 AM — The Spec
By 8:15 AM, a comprehensive project specification existed — approximately 15 pages covering problem statement, product architecture, pattern knowledge base schema, CLI interface design, business model, go-to-market strategy, competitive analysis, development phases, and IP strategy.
The tagline:
"The safety net for vibe-coded software — catches what frontier models miss, teaches what developers forgot."
8:15–8:30 AM — The Academic Angle
Before the spec was even cold, I identified a distribution channel: CIS/MIS professors I'd built relationships with through IACIS conferences and my editorial board work at the Journal of Computer Information Systems.
The framing was immediate. Professors are stuck in a binary "ban AI vs. allow AI" debate with students. CodeSentry gives them a third option — allow AI, but instrument the learning. Require students to run the tool on every submission. The output shows whether a student understood what they submitted or just pasted what the AI gave them.
8:30 AM — Handoff
This is where Part 1 ends and Part 2 begins.
I took the spec to Jane and Morgan. Morgan — an AI Product Manager — reviewed the Phase 0 requirements and produced a precise, testable JSON specification. Then the crew started building.
Part 2: Spec → Build → QA → Ship
The Crew
The Spec Gets Teeth
Morgan took the 15-page strategic spec and translated it into an implementable Phase 0 JSON specification. The goal was explicit from the spec: "Validate core hypothesis: developers prefer tools that teach, not just flag."
Morgan's output defined 5 initial patterns (CS001–CS005) with full detection rules, CLI interface with three subcommands, directory structure, key interfaces, test fixtures for each pattern, success criteria including "<5% false positive rate on test corpus," and explicit non-goals.
DevCrew Builds
DevCrew received Morgan's JSON spec and built the implementation. Core package, pattern detectors, test fixtures, project files. All acceptance criteria from the spec were validated before handoff to QA.
DevCrew didn't decide what to build. DevCrew executed a spec.
QA Rejects
QAEngineer didn't rubber-stamp the build. The review methodology included code review, CLI testing, output mode testing, exit code verification, edge case testing, and false positive analysis.
That last category — false positive analysis — is where things got interesting.
- BUG-001 (HIGH): False positives on legitimate Python stubs. CS002 was flagging @abstractmethod decorated methods, Protocol stub methods, and @overload type hint stubs as "placeholder code." These are legitimate Python patterns that must have empty bodies.
- BUG-002 (MEDIUM): Flagging stubs without TODO/FIXME. The spec explicitly stated CS002 should detect "TODO/FIXME comments paired with placeholder implementations." The implementation was flagging any function with a pass or ... body, even without a TODO comment anywhere nearby.
Verdict: NOT APPROVED. Blocking bugs.
The build was handed back to DevCrew with specific bugs to fix and specific files to change.
DevCrew Fixes
DevCrew addressed both blocking bugs: added decorator and class inheritance checking for BUG-001, and made TODO/FIXME a required condition for BUG-002. A new test fixture was added to verify the fixes.
QA Approves
QAEngineer re-validated both fixes. Full regression across all 7 fixtures: all pass. No regressions introduced.
Verdict: APPROVED. Bug fixes verified, no regressions. Ready for Phase 0 release.
What Actually Shipped
Default output — clean, scannable:
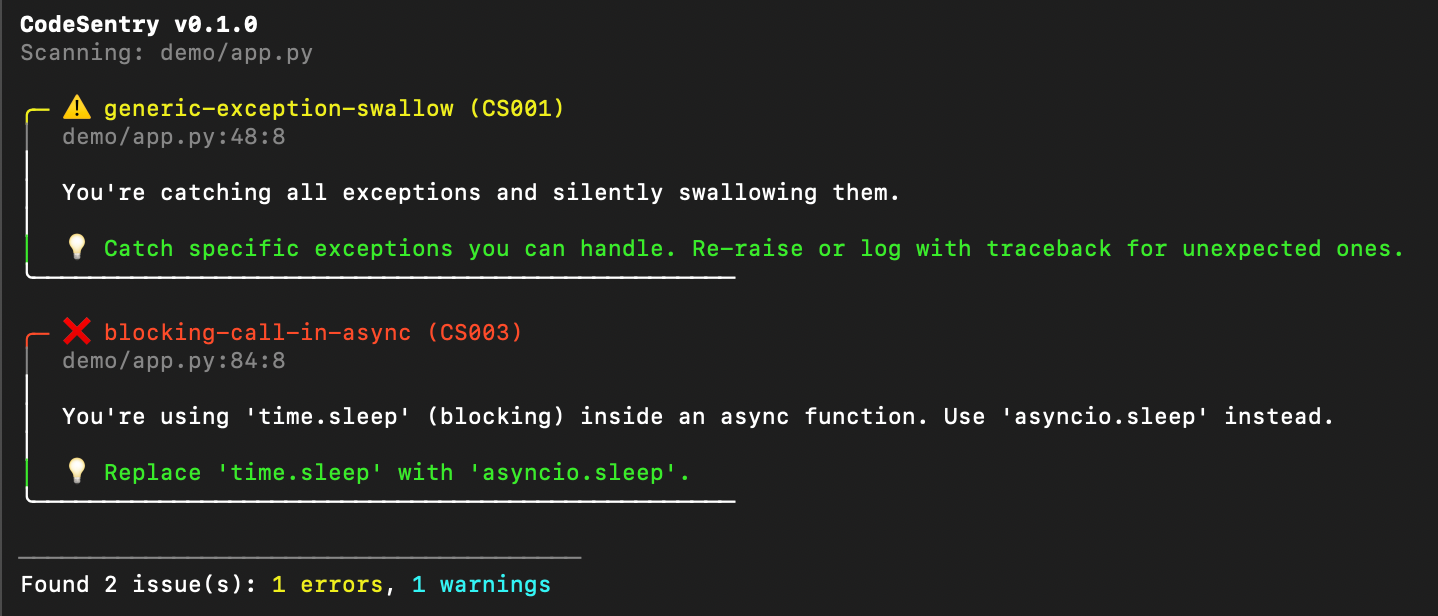
With --teach mode, each issue includes: what's happening, why it matters, how to fix it, code examples (bad and good), and how to spot it yourself next time:
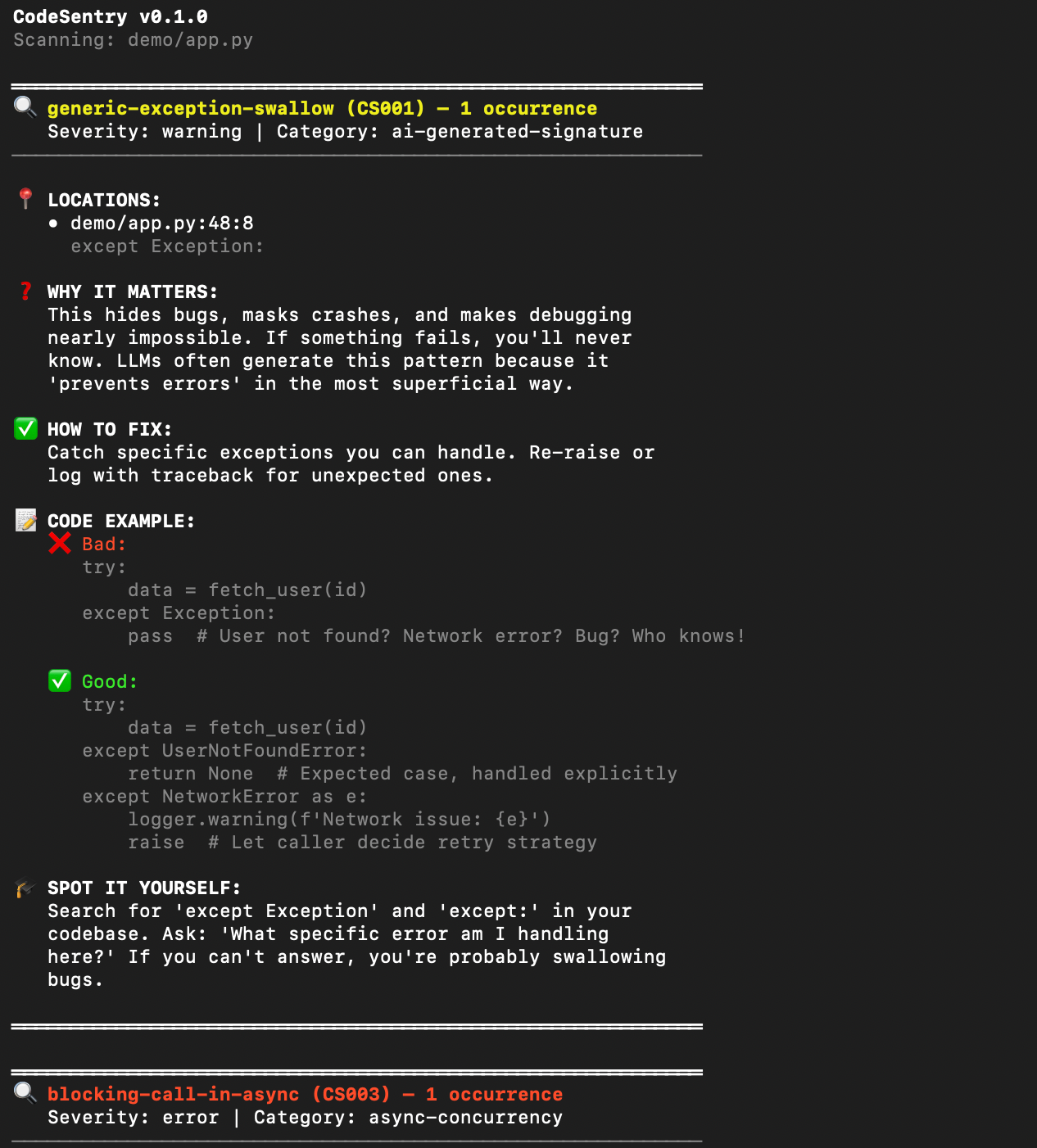
That last section — "spot it yourself" — is the product. Not just catching bugs. Teaching developers to recognize patterns independently.
The Timeline
| Time | Step | Who |
|---|---|---|
| 7:03 AM | See LinkedIn post, start conversation | Mike + Claude |
| 7:05–7:20 AM | Explore angles, converge on product | Mike + Claude |
| 7:20–7:45 AM | Product decisions, real-time research | Mike + Claude |
| 7:45–8:15 AM | Write 15-page project spec | Mike + Claude |
| 8:15–8:30 AM | Academic distribution strategy | Mike + Claude |
| ~8:30 AM | Handoff to Morgan | Mike → Jane |
| ~8:38 AM | Morgan produces Phase 0 JSON spec | Morgan |
| ~8:40 AM | DevCrew delivers implementation | DevCrew |
| ~8:51 AM | QA rejects — blocking bugs found | QAEngineer |
| ~9:00 AM | DevCrew fixes both blocking bugs | DevCrew |
| ~9:10 AM | QA re-validates, approves | QAEngineer |
From LinkedIn screenshot to QA-approved, tested, bug-fixed prototype: one Saturday morning.
The Meta-Lesson
CodeSentry exists because AI-assisted development erodes debugging skills. CodeSentry was built using AI-assisted development.
But there's a structural difference, and it maps directly to the Anthropic study's findings.
The study identified six interaction patterns. Three scored below 40% — AI Delegation, Progressive AI Reliance, Iterative AI Debugging. Three scored 65% or above — Conceptual Inquiry, Hybrid Code-Explanation, Generation-Then-Comprehension.
The crew operates in the high-scoring patterns by design:
- Morgan generates specs, not code. The human comprehends and approves the spec before any code is written. That's Generation-Then-Comprehension at the product level.
- DevCrew executes specs, not ideas. DevCrew doesn't decide what to build. The human decided. DevCrew implements. Separation of decision from execution.
- QAEngineer rejects bad work. QA found BUG-001 by testing against legitimate Python patterns that require empty bodies. That's not running test cases. That's understanding the language ecosystem well enough to know what the spec missed.
- The human stays in the loop. I set direction, made product decisions, identified the distribution channel, and approved the final output. I didn't disappear after handoff.
AI-assisted development isn't the problem. Unstructured AI-assisted development is the problem.
Appendix: The Crew
- Jane — Apex intelligence. Coordinates the crew, maintains context across sessions, handles orchestration and strategic conversation.
- Morgan — AI Product Manager. Transforms requirements into testable JSON specifications. Doesn't write code. Writes specs that code gets written from.
- DevCrew — Builder. Executes specs. Writes code. Doesn't make product decisions. Hands off to QA when done.
- QAEngineer — Reviewer. Reads code, runs tests, tests edge cases, writes bug tickets. Rejects bad work. Doesn't fix code — hands it back with specific issues.
Each agent has a SOUL.md defining their role, tone, and boundaries. The separation of concerns isn't just architecture — it's how you prevent the competency death spiral the Anthropic study describes.
Mike Bumpus is the founder of AI Cabinet Method LLC (dba DigitalEgo) and the creator of Crewly Codes. He builds AI coordination frameworks from a converted tool shed.
This article documents a real build session on January 31, 2026. All timelines, bug reports, and code artifacts referenced in this piece exist as version-controlled project documentation. No part of this workflow was staged or reconstructed after the fact.